
Businesses of all sizes rely on data to inform decisions, predict trends, and drive growth. But there’s a catch: getting that data to where it’s needed is an enormous challenge. Deploying a complete modern data stack – the collection of tools for collecting, processing, visualizing data and more – is a journey through a maze of configuration, management, and scaling hurdles. And let’s face it, the journey isn’t always a smooth one.
If you’ve ever tried to set up a data stack from scratch, you know the frustration. Each tool has its own setup process, requirements, and integrations. Multiply that by the number of tools in the stack, and it quickly becomes overwhelming. In this article, we’ll explore the biggest challenges in deploying a data stack and why the industry desperately needs a new, simplified approach.
The struggle to build a cohesive modern data stack
Fragmented data tools and complex integrations
Building a data stack often feels like assembling a puzzle without knowing if you have all the pieces. Data teams need a variety of tools for ETL (Extract, Transform, Load), orchestration, storage, and visualization. Yet these tools come from different vendors, and each has its own installation process, dependencies, and integration quirks.
This fragmentation means that data engineers spend a significant amount of time configuring integrations instead of actually analyzing data. They have to navigate different APIs, set up authentication across platforms, and troubleshoot when one piece of the stack fails. It’s no wonder that in most organizations, valuable resources are spent maintaining the stack rather than deriving insights from it.
Scalability and maintenance challenges
As companies grow, so does the volume of data they collect. Suddenly, the tools that worked well during the early days of the business are no longer adequate. Scaling a data stack isn’t as simple as buying more server space; it requires tweaking configurations, adjusting data pipelines, and sometimes even swapping out tools.
Every new tool and adjustment requires testing to ensure compatibility across the stack. And when tools need frequent updates to stay functional and secure, maintaining a scalable stack becomes a burden. Many companies hit a point where they’re spending more time patching up the data stack than they are getting insights from it.
Security and data governance
A complex data stack means there are multiple entry points for potential security risks. As data moves through the stack, it needs to be protected at each stage. Permissions and access must be carefully managed across tools to prevent unauthorized access. Additionally, regulatory requirements add another layer of complexity, especially in industries like finance and healthcare.
The more tools there are, the harder it becomes to establish a consistent data governance framework. Organizations may end up with data silos or shadow IT setups where different teams have their own methods for storing and processing data. This lack of centralized control is a recipe for compliance risks and data breaches.
The impact of a convoluted data stack on businesses
High costs and inefficiencies
Building and maintaining a data stack is expensive. Beyond the cost of purchasing software licenses, there’s the hidden cost of engineering hours spent on configuration, maintenance, and troubleshooting. And when things go wrong, data downtime can lead to missed business opportunities, making the stack an indirect, but significant, financial liability.
Delayed time-to-insight
With data pipelines prone to bottlenecks, delays are inevitable. Each tool in the stack adds another layer that data must pass through before it reaches the people who need it. When decision-makers are relying on outdated or incomplete data, the quality of their decisions suffers. A convoluted data stack isn’t just a technical issue; it’s a business risk.
Talent burnout
Data engineers are in high demand, and for a good reason: they have the skills to turn raw data into actionable insights. But when they’re constantly stuck fixing and patching a fragmented stack, job satisfaction can plummet. In many cases, engineers leave their roles because they’re bogged down by maintenance tasks rather than engaging in strategic, meaningful work. High turnover among data engineers only makes the problem worse.
How Visionarist is transforming data stack deployment
It’s clear that the traditional approach to building a data stack isn’t sustainable. Businesses need a way to deploy their data stack quickly and efficiently, without the endless headaches of traditional deployments.
At Visionarist, we recognized the issues that businesses face when deploying and managing their data stacks, and we set out to create a solution. Visionarist’s platform brings the concept of “one-click deployment” to life, allowing businesses to set up an entire data stack in minutes, not weeks.
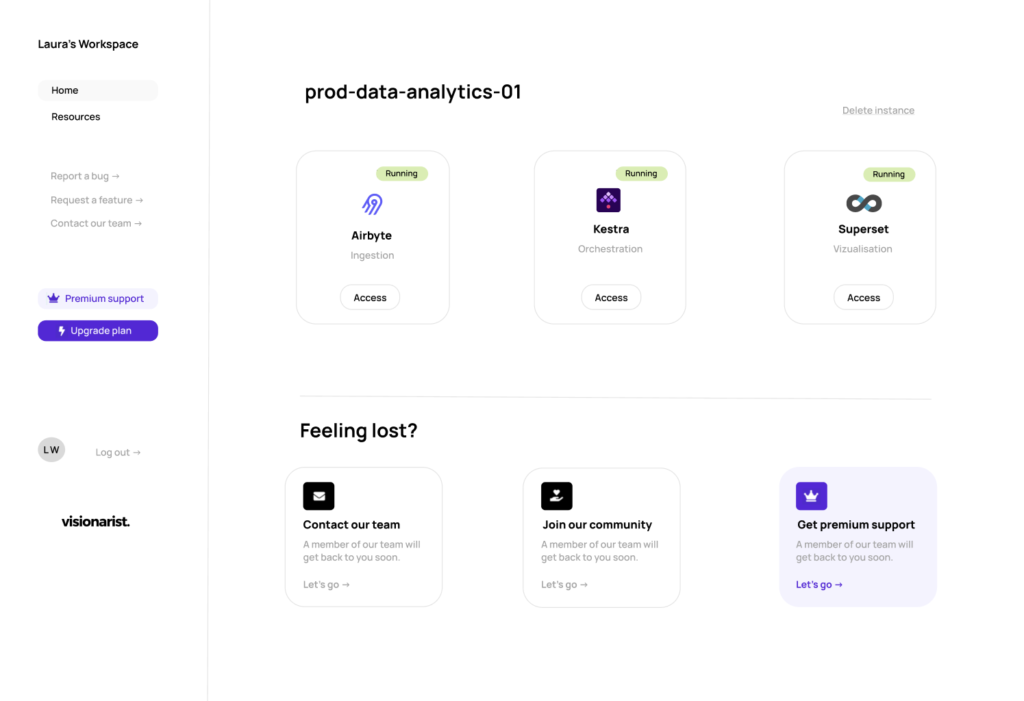
Let’s look at what Visionarist has to offer:
One-click data stack deployment
Imagine being able to set up your entire data stack with a single click. Instead of spending weeks on setup, you will be able to deploy a complete, pre-configured data stack in minutes. With Visionarist, you can deploy powerful open-source data tools like Airbyte or Superset. No need to configure each tool individually, Visionarist’s platform deploys all at once, fully integrated and ready to use.
Data privacy and security with self-hosting
Data privacy is more critical than ever. Unlike other data plaltforms that require data to be stored on their servers, Visionarist allows businesses to self-host their data stack. This means data remains in your control, making it a great choice to comply with GDPR and security standards.
Centralized user management
Instead of juggling multiple logins and access controls for every tool in your stack, centralized user management consolidates everything into a single interface. This means your team can easily onboard and offboard users, assign roles, and control permissions across all integrated tools without the hassle of logging into each one separately.
Built-in scalability
Visionarist is build with growth in mind. Whether you’re processing small datasets or massive streams of data, your data stack scales with your needs, allowing your data capabilities to evolve as your business grows. With Visionarist, adjust to the organization’s needs without complex reconfiguration or tool replacements. This means automatic scaling options, as well as easy upgrades when additional features or higher processing power are required.
Soooo, it’s time for a data stack revolution!
You may have experienced it: traditional data stack deployment model is no longer sufficient for the fast-paced demands of modern business. Companies need a way to deploy and manage their data stacks without the headaches of fragmentation, complexity, and security risks. Visionarist’s one-click deployment solution is designed to be that game-changer, offering simplicity, control, and scalability in one package.
As data continues to play an ever-important role in decision-making, organizations can’t afford to let deployment challenges slow them down. Visionarist’s solution is here to transform the way businesses think about data, making it easier than ever to turn data into insights.